Evidence-Based Scheduling
FogBugz uses a sophisticated statistical algorithm called Evidence-Based Scheduling (EBS) to produce ship date probability distributions. EBS was developed at Fog Creek Software, and is exclusive to FogBugz.
EBS uses a statistical method called bootstrapping that we have found does a very good job of predicting software schedules.
The first time you use EBS, it will probably come up with a ship date that seems much later than you were hoping for, and you might despair. But after a while, you'll understand why it's doing this, and you'll see that the schedule that EBS generated, pessimistic though it seemed, was actually right on the mark. EBS is an algorithm that understands why software projects come in late and actually incorporates that into its estimates, mathematically. EBS actually looks at the historical track records of every person who enters estimates, and assumes that the future will look a lot like the past.
How the algorithm works
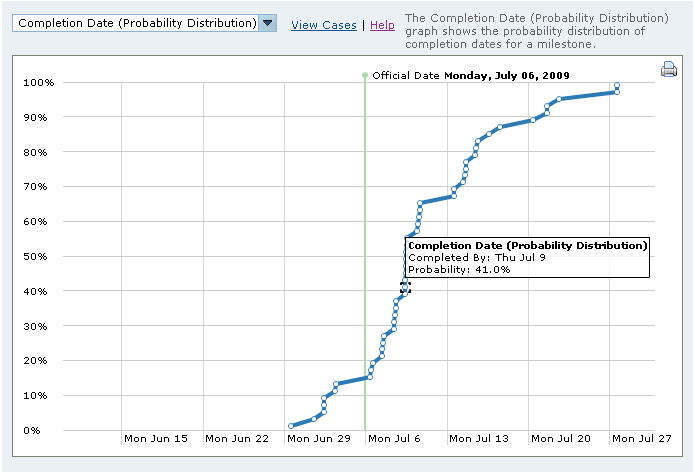
EBS doesn't give you a single ship date. Instead, it produces a probability distribution curve. That means that for any given date, it tells you what the probability is that you will ship by that date.
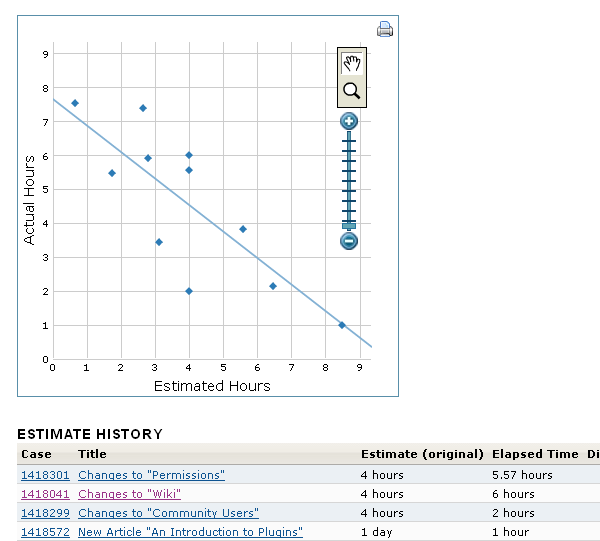
To do this, EBS needs to keep track of the historical track record of each estimator. An estimator's track record is just a list of all the features that they estimated which were implemented and closed. In order to be considered a historical estimate for a user, a case must be estimated by that user, have time charged against it, and then be resolved and closed. The resolution must be "Completed", "Fixed", "Implemented", or "Responded." For each completed feature, EBS looks at the original estimate entered and the actual time elapsed. It divides estimate by elapsed to get the velocity of that feature's implementation. A feature that takes twice as long as expected has velocity 0.5.
EBS collects as many as 200 recent velocities from each estimator. If an estimator has no historical track record or has fewer than six completed features, EBS backfills that track record with six velocities that reflect a very poor estimator. This way, in the absence of historical data, EBS assumes the worst about the estimator.
Once EBS has a track record for each estimator, it can simulate the future. EBS does this simulation 60 times. In each round of the simulation, and for every feature that needs to be implemented, it uses a velocity randomly chosen from the estimator's track record.
When EBS calculates the schedule repeatedly, for 60 possible futures, it assumes that each possible future will occur with 1/60th probability. This gives it a probability distribution curve with 60 data points.
To make a schedule for one developer, EBS adds up all the estimates of that developer's features to get a total number of hours of work. But instead of actually taking the estimates at face value, it uses adjusted estimates, which reflect the estimator's historical track record.
To get an adjusted estimate, EBS starts with the estimates entered into FogBugz (minus elapsed time). Then it picks a pseudo-random number n between 1 and x, where x is the number of velocities in the estimator's track record. It then sorts the velocities in ascending order and picks out the nth velocity from the list. Since n is real, it actually picks the two closest velocities - the (floor(n))th and the (floor(n+1))th - and interpolates linearly between them to get a single velocity. In other words, EBS picks a random velocity with the same distribution as that estimator's historical velocities.
Next, EBS divides the entered estimate for the feature by the randomly chosen velocity and uses this as the adjusted estimate for this particular imagined future. Unless every estimator has a perfect track record, each of the 60 futures will be a little bit different.
EBS scales adjusted estimates if the developer does not work 100% on that project; for a developer who works 20% time on that project, a 1 hour feature will be scaled to 5 hours.
Once EBS has the sum of a developer's adjusted estimates, it spreads those hours out on the calendar, the developer's work schedule, vacations and holidays, and figures out the calendar date when they would be done. It also takes any project dependencies into account, and assumes that the developer will do all priority 1 features first, followed by all priority 2 features, etc.
In each iteration, EBS calculates the schedule for each individual developer, and then assumes that the project will ship on the date that the last developer finishes their last task.
Why the algorithm works
EBS is not affected by the details of how estimators come up with their estimates. For example, it doesn't really care if they include coffee breaks in their estimates or not, as long as they're consistent about it.
- Example. Adam has a bunch of features estimated at 1 hour. He takes a three hour coffee break every day, so he gets 5 of these one hour features done every day. On his time sheet, one of these features actually takes 4 hours even though it was estimated at 1 hour, because he took the coffee break in the middle of working on that feature. Eventually, his track record shows that he has a 80% chance of working at velocity 1.0 and a 20% chance of working at velocity 0.25. When EBS runs, 20% of the time that it sees Adam estimating something at 1 hour, EBS will actually use a calculated estimate of 4 hours, which perfectly corrects for Adam's very predictable coffee breaks.
EBS degrades very gracefully in the absence of historical data.
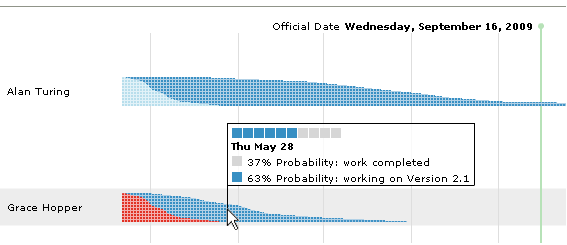
- Example. Bonnie is new to the team, so EBS has no track record for her. EBS uses a synthetic track record corresponding to a lousy estimator. Her calculated estimates are much more scattered than her entered estimates, which makes the probability curve much more gradual. The more people you have on a team without track records, the more gradual the probability curve is, reflecting the reality that your schedule is not very trustworthy.
- Example. Over the next year, Bonnie proves herself to be a consistent estimator -- consistently underestimating each task by half. Even though she seems like a "bad" estimator, her track record fills up with velocities very near 0.5. When EBS runs, the calculated estimate is almost always 2 times the entered estimate. EBS actually gets the final date right, and in fact there is very little variation in this date because Bonnie is a reliable underestimator, so the probability curve is very steep, reflecting the reality that your schedule is quite trustworthy.
EBS handles rare outliers very well.
- Example. Chauncey is a member of the company gardening committee. Twice a year, in the spring and fall, he takes off two weeks to plant annuals in the company garden, and leaves the clock running on whatever feature he left in progress. There is a certain small probability, reflected in his track record, that a particular short feature will actually take more than two weeks because he's off gardening. Even though this seems like an unusual outlier and you might be tempted to discard the data point, it actually gives EBS very useful information; with some probability, EBS will generate a schedule in which Chauncey takes a ridiculously long time to do something, and that probability is based on evidence. Over the course of a one year schedule EBS is very likely to correctly compensate for Chauncey's gardening excursions.
EBS handles estimators whose estimates improve.
- Example. By her third year on the job, Dahlia is much better at estimating than she was when she started. Because EBS only looks at the last 200 completed features in constructing a track record, as time goes on, her calculated estimates get closer and closer to her entered estimates.
EBS correctly accounts for real-world estimating errors.
- Example. It is far more likely for a feature to go over than to come in early, and when it does go over, it can go over by much more than other features could come in early. It's easy to imagine an 8 hour feature slipping to 16 hours, 24 hours, or 40 hours as things go wrong and new bugs and new work is discovered, but it's impossible to imagine an 8 hour feature taking much less than 2 hours. In realistic schedules, this means that features don't really balance themselves out: early features do not fully compensate for late features, and you can never make up for all that lost time by doing other features more quickly. EBS understands this, measures this, and accounts for this perfectly based on actual historical data.
EBS correctly accounts for vacations and holidays.
- Example. Francine is the developer with the most work left -- she has about two weeks of work. Unfortunately, in two weeks, she's scheduled to go on a long overdue vacation that is three weeks long. There is a 50% chance that she will finish her work before the vacation. EBS will show a probability distribution curve that reflects the 50% chance that you'll ship in two weeks, with a big flat step: to get to 51% probability, you have to wait five weeks. When you see this unusual flat step in the probability distribution, you can move a feature or two from Francine to George, increasing the probability that you will ship three weeks earlier.
EBS correctly accounts for lazy developers.
- Example. One member of the team, Hilda, is really lazy about entering estimates and never keeps her time sheets up to date. When she does enter estimates, they're wildly off the mark. EBS reflects this correctly, showing a very wide bar for her on the developer ship date chart, and it is reflected accurately in the project schedule, which becomes more gradual to correctly account for the poor data you're getting from Hilda. Her manager Ivan decides he's had enough and starts giving her paychecks with about the same consistency as she enters estimates and timesheet data. Soon, her track record gets better and the project schedule becomes steeper as the data become better.
EBS correctly accounts for team leaders who still like to meddle in the code.
- Example. Joel has been the Big Boss for six years now, but he still makes the developers assign features to him which he works on maybe one day every two weeks. There are two ways to account for this in EBS, both of which work perfectly. One way is that Joel goes to his personal schedule and declares that he spends 10% of his time on features tracked in FogBugz. Now when he enters a one day estimate, EBS will treat this as taking two calendar weeks. Another way to account for it is that he leaves the clock running even when he's not working on features at all. His track record shows that he commonly works at a velocity of 0.10. Then the calculated estimate of a one day feature is likely to be ten working days. The cool thing is that EBS produces the same, correct results no matter how you choose to use it, as long as you're consistent.